The Back Door into Linear Algebra
I've been thinking back to the maths syllabus I had in secondary school. Geometry and vectors were in there, no question. But a few areas, matrices among them, just weren't. How much linear algebra a Korean state school covered shifted from one curriculum to the next, and the years I went through happened to land on the lean side.
At the time I had no sense it was even missing. You don't notice what you were never taught. There was calculus, there was probability and statistics, and I figured that was roughly what maths was. If anything sticks out now, it's that I never once heard an answer to "why are we learning this" in a maths lesson. And it wasn't that the answer was missing so much as the question never came up at all.
This only dawned on me much later, once I got properly stuck into AI work. Handling embedding vectors, staring at attention matrices, chewing over what on earth gradient descent is actually doing. Those moments piled up. Early on I was just focused on getting the thing to run. I cared more about what you could do with a transformer than what a transformer was. If the output came out and the loss dropped, I was happy.
Then at some point a strange sort of awareness started to grow. The realisation that I didn't really know what the things I touch every day actually were. I could write the code to call a transformer, but I couldn't understand what was going on inside it, mathematically. What exactly attention is as an operation, what kind of space an embedding space actually is, what map you're really applying when you multiply by a weight matrix. There was a clear gap between being good at wielding a tool and understanding it.
I knew how to write code that multiplies matrices, but why that product means what it means stopped at the how-to level. I knew how to call np.matmul. What it was doing as an operation stayed fuzzy. I'd been running things in that fog for ages, not really knowing. When I couldn't put up with the fuzziness any longer, I finally opened a book.
Meaning has coordinates
I remember the first time I worked out the cosine similarity between two embeddings. A few lines of code that turned a handful of words into vectors and then measured the angle between them.
tensor([[0.72]]) tensor([[0.13]])
I looked at the result and stopped for a second. king and queen came out at 0.72, king and banana at 0.13. Words that were close in meaning were close in position too.
Back then I couldn't unpick what that meant straight away. But a strange little crack opened up. Meaning, an abstraction, had been moved across into something concrete, a position in space. More precisely, moving it across was possible at all. That you could lay out something as invisible as meaning along a set of coordinates.
A few days later the second jolt followed. I saw an equation in something someone had written.
At first it threw me, so I read it again. It was saying you could subtract and add words. Words. And that the result turns into another word. Take king, strip out the bit of meaning that is man, add in the bit that is woman, and you get queen. Meaning was open to arithmetic. And to the simplest arithmetic going at that, adding and subtracting vectors.
Sit with it for a while and it feels less like something happened and more like something had always been the case. Meaning had carried that kind of structure all along, and we'd just found the coordinate system that shows it off. Saying an embedding has trained well is, near enough, an after-the-fact discovery that meaning, the abstraction, had the properties of a vector space from the start.
When you think about it, that's the job linear algebra does. Lay down the stage of a vector space, and on top of it relationships get expressed as distance and direction. The distance between two points becomes how different they are, and the angle they make becomes how alike they are. An equation like suddenly hooked up with intuition. The equation didn't come first. The equation was a transcription of a property of the space.
This was the first time it felt like linear algebra wasn't just a tool but a language. Some kinds of relationship are said most naturally only when you say them in that language. king − man + woman ≈ queen was the sort of relationship you can't put across in Korean, or in any prose. It was a fact that only comes out that cleanly when you say it with vectors.
Studying it back to front
I remember the first day I opened the book. I had Strang's first MIT OCW lecture playing and a notebook open in front of me. On screen he chalked up and started unpacking what it meant.
At first I had no idea where to start or how to look at any of it. Korean material, English lectures, textbooks, OCW. There were plenty of ways in, and any of them would let you through the door. In the end I kept a few going at once and worked through it slowly. Less reading one book cover to cover, more pulling up whatever chapter I needed at the time and chewing it over.
One thing was odd. People who'd learnt LA the regular way would often say "I don't get why we're learning this", and I had almost none of that. I already had the answer to why. Embeddings live there, attention is defined there, gradients flow there. Starting the study already knowing what it's for turned out to be a strangely big advantage.
The fact that I'd done it back to front stopped feeling like a flaw and started feeling more like a condition. Every definition and theorem came with an application I'd already seen. The abstraction wasn't something I was meeting for the first time. It was the work of unpacking an abstraction while holding where it shows up right there in my hand.
Every matrix, three steps
The second discovery came later. I was carrying that sense of linear algebra as a language and digging about a bit more inside it. Then I pulled up short at a theorem called SVD.
SVD, Singular Value Decomposition. The theorem that any matrix breaks down into three steps.
Rotate (), then stretch (), then rotate (). That's all there is to it. Every matrix was, in the end, doing this. Rotating, stretching, rotating.
Said out loud it sounds abstract, but one picture sorted the whole thing out. Draw a unit circle on a 2D plane, then multiply some arbitrary matrix into every point on it. The result is always an ellipse. However the unit circle gets warped, the warping always follows the shape of an ellipse. The two axes of that ellipse were exactly the singular values telling you how much it stretches, and the directions those axes point in were the directions the rotation matrices are responsible for.
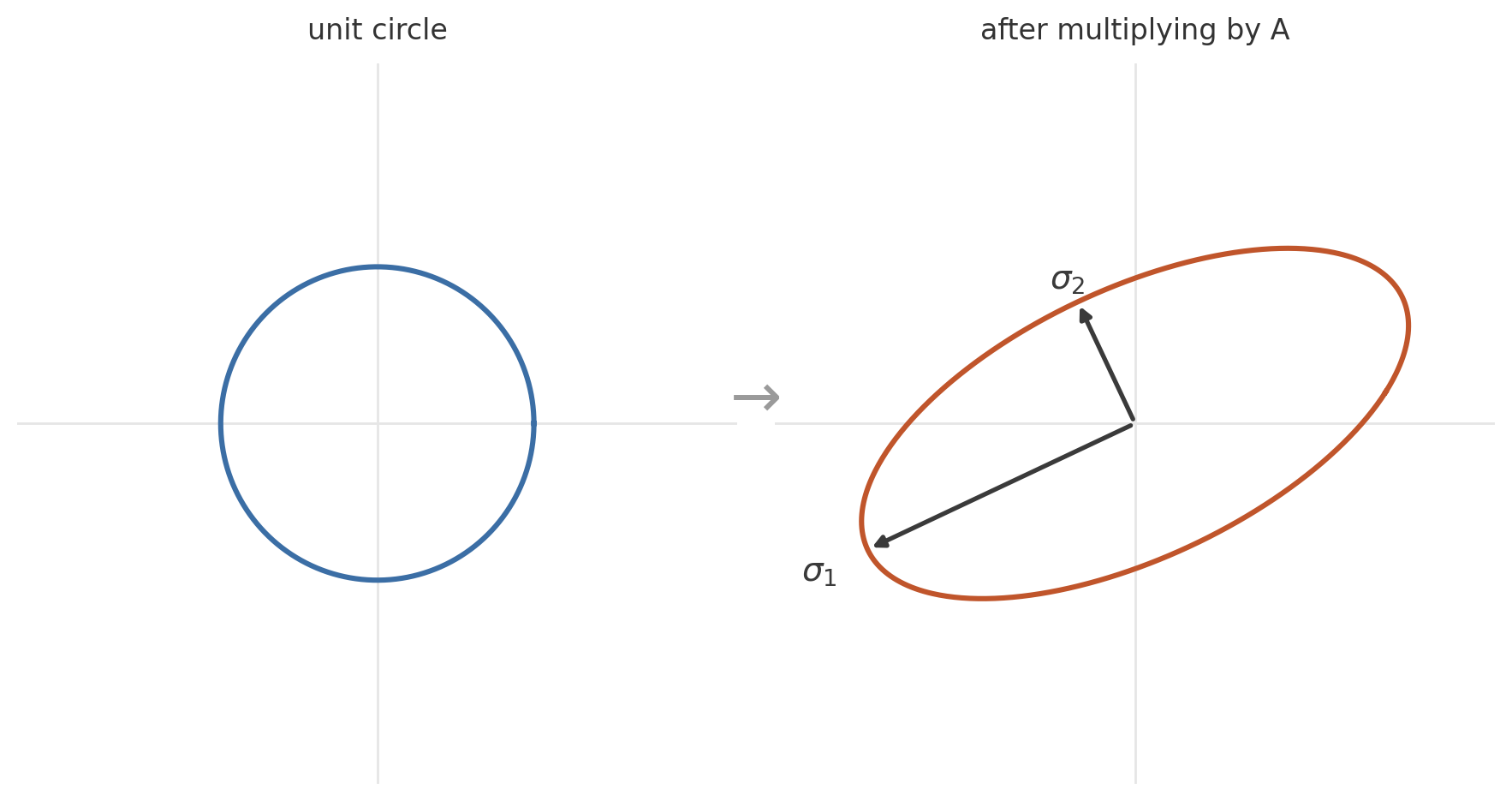
The bare fact that such a decomposition exists for every matrix shook me up in an odd way. There's no oddball variant hiding away in some corner. Any linear transformation reduces, without exception, to these three steps. At first I doubted why that should be possible. Then I slowly came round to why wouldn't it be. So long as a linear transformation is, in the end, a map that handles space consistently, the trace it leaves can only come out as stretching along orthogonal axes. The rotation soaks up the asymmetry. Beyond that there's nothing. The way I saw matrices suddenly fell into order.
After that, every time I ran into some matrix, SVD would surface in the back of my mind. Which way does this matrix rotate, along which axis does it stretch, then which way does it rotate again. What a matrix does wasn't a mystery any more. At an abstract level, at least.
A warmer kind of beauty
Carry discoveries like these around and one question naturally tags along. What exactly was the thing I'd found beautiful.
In A Mathematician's Apology, G.H. Hardy picks out unexpectedness, inevitability and economy as the conditions for mathematical beauty. When I first saw SVD I think all three were there.
First, unexpectedness. There was no way to guess in advance that a matrix would break apart into a form that tidy. I'd thought of a matrix as just a grid of numbers. That a structure of rotate, stretch, rotate was hiding behind that grid was completely out of the blue. And the universality of it, that every matrix shares that structure, ramped the surprise up another notch.
Then, inevitability. Once you've taken the decomposition on board, no other form comes to mind. That one picture of a unit circle turning into an ellipse shut off the alternatives. There was no nagging sense of, couldn't you decompose it some other way. It settled in as a feeling that it had to be that way.
Last, economy. The equation itself has nothing left to shave off. , , . Three objects finish off any linear transformation. It's an equation that reduces matrices, something endlessly varied, down to three orthogonal parts, and there isn't a single character of fat on it.
Hardy's criteria on their own left something out, though.
Mathematics, rightly viewed, possesses not only truth, but supreme beauty, a beauty cold and austere, like that of sculpture.
That's Russell. Part of it rings true. The sense of a theorem being shut tight the way a theorem should be, the way that holds a person at arm's length, cold is spot on for that.
But what I'd run into was a somewhat warmer sort. The warmth of discovery, I suppose you'd call it. Not coming across a sculpture someone had already carved, from a distance, but the feeling of having set foot inside it myself. Not a cold form but a space you could walk into. There was time spent going through that space one step at a time, feeling out how it comes to be like this with my hands, and that time itself lent the discovery some warmth. A beauty closer to taking part than to looking on.
I found out later that Paul Lockhart says something along the same lines in A Mathematician's Lament. A lament that school rarely gives you the chance to meet maths as art. One image he uses stuck with me. What if music education spent twelve years making you memorise sheet music and never once let you hear any music. That, he says, is what maths education is doing to maths. In my case I ended up hearing that music down a back route. The music school never played, coming in from a different door.
Just the entrance
This far is the entrance. The way further in from here is still wide open, plenty of it left.
What eigenvalues are actually saying. The fact that a transformation has directions it doesn't twist, and what those directions tell you about a matrix's nature. What sort of geometric operation attention essentially is. How the dot product of key and query becomes similarity, and how that similarity moves across into a learnable distribution. Why a tensor product is the same thing as multilinearity. What universal property the act of multiplying two spaces together carries.
There are little signposts, questions, dotted about all over the place. A landscape is laid out that I want to go through one spot at a time. Working through them one by one and writing them up looks like it'll be the job ahead.
This post is the first note from that entrance. Not a post trying to draw the whole landscape, but one that points out the landscape is there. One that jots down what was warm about it once I'd set foot inside. The posts after this will go past this entrance and reach the spots within it directly.